MatchDiffusion:
Training-free Generation of Match-Cuts
ICCV 2025
1†Work done while at KAUST, now at Meta.

Autumn leaf falling → Butterfly fluttering (Straight Cut)

Circular highway interchange → Ice skating in circles on a frozen lake (Alpha Blended)

Flower blooming → Fireworks bursting over a calm lake (Alpha Blended)
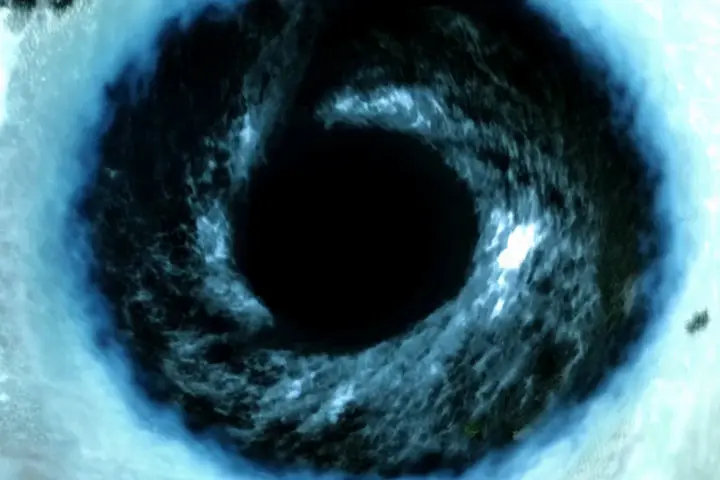
Ocean vortex swirling → Close up blue eye (Flickering)

Waves lapping on shore → Ants marching on forest floor (Straight Cut)
MatchDiffusion enables the automatic generation Match-Cuts, i.e., visually consistent and semantically distinct scenes.
Match-diffusion is a training-free approach that employs joint and disjoint diffusion stages to balance coherence and divergence, producing high-quality transitions suitable for diverse artistic needs.
What Are Match-Cuts?
A Match-Cut is a film editing technique where two shots are seamlessly connected by matching their visual, structural, or conceptual elements. These cuts guide the viewer’s attention and create a smooth transition while maintaining narrative or aesthetic coherence.
Match-Cuts are often used to highlight symbolic relationships or temporal continuity between scenes. For more Match-Cuts' examples visit the website:
https://eyecannndy.com/technique/match-cut.

Match-Cut from Turkish-airlines Advertisement (Straight Cut)

Match-Cut from So Not Worth It -TV series (Alpha Blended)

Match-Cut from Delta Airlines Advertisement (Straight Cut)
MatchDiffusion
Given two prompts (\(\rho'\), \(\rho''\)) describing different scenes, our goal is to generate a pair of videos (\(x'\), \(x''\)) that adhere to their respective conditions while remaining visually cohesive for match-cut transitions.
The two videos can be combined in a match-cut, for instance, by joining the first half of (\(x'\)) with the second half of (\(x''\)) via a Straight Cut, Alpha Blending, Flickering between them, among other editorial options.
This approach enables a smooth transition between different semantic scenes while preserving consistent visual characteristics.
Previous works have observed how diffusion models inherently establish general structure and color patterns in early denoising stages, with finer details and prompt-specific textures emerging in later stages.
We build on this property to generate videos amenable for match-cuts.
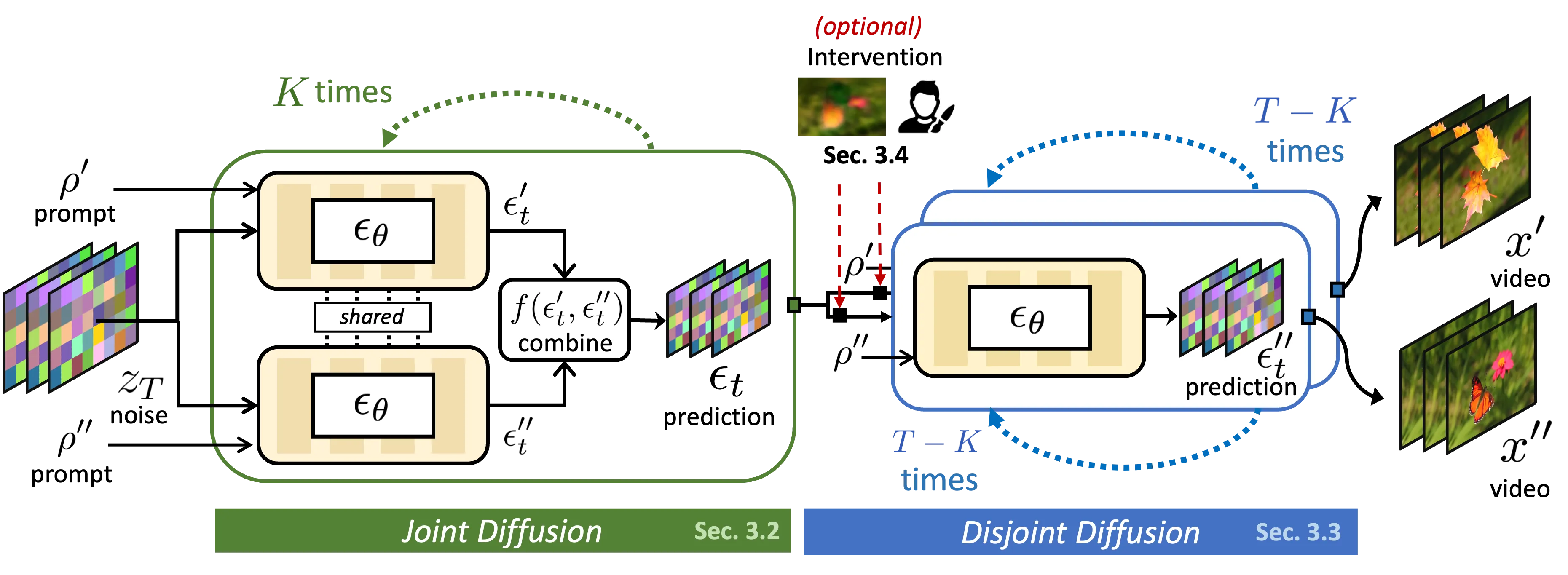
In particular, we propose MatchDiffusion, a two-stage training-free pipeline comprising: (1) Joint Diffusion, where we set up a shared visual structure based on both prompts, followed by (2) Disjoint Diffusion, where each video independently develops the semantics corresponding to its prompt.
Pipeline Figure
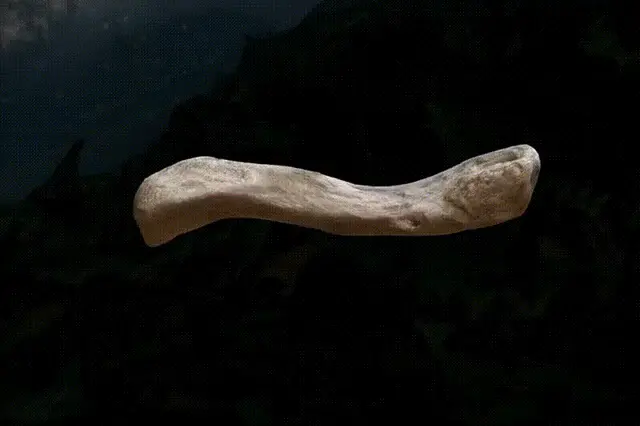
Reproducing Kubrick's Famous Match-Cuts
Our pipeline enabled us to reproduce what is arguably the most famous Match-Cuts of all time: the bone-to-spaceship transition in Stanley Kubrick’s 2001: A Space Odyssey. This iconic moment seamlessly transitions from a prehistoric tool to a futuristic spacecraft, symbolizing the leap in human evolution. Below, we present the original Match-Cuts alongside our reproduction using MatchDiffusion.

Original: Kubrick's Bone-to-Spaceship

Reproduction: MatchDiffusion
More Results from MatchDiffusion
Below, we showcase additional results generated by MatchDiffusion, demonstrating its ability to produce seamless and visually compelling Match-Cuts across a variety of prompts and transitions.
We form Match-Cuts via a Straight Cuts, Alpha Blending, or Flickering between them.

An artist painting on a canvas → A chef slicing vegetables (Alpha Blended)

Vintage steam train → Tranquil river winding through forest (Straight Cut)

Volcanic crater from above → Eye blinking in close-up (Alpha Blended)

Latte art bear → Bear peeking from behind tree (Straight Cut)

Leaves rustling in autumn → Confetti swirling in celebration (Flickering)

Driftwood in river → Sand dunes shifting in desert (Straight Cut)

Flames flickering → A volcano erupting (Alpha Blended)

Highway panning → Pier gliding along ocean waves (Straight Cut)

Lighthouse beam on ocean → Car headlights cutting through fog (Straight Cut)

Sailboat gliding across lake → Hawk soaring over canyon (Straight Cut)

Whiskey bottle on wooden table → Cozy cabin in snowy woods (Straight Cut)

Dew on a spider web → Sunlight on a calmed lake (Flickering)

Kaleidoscope turning → Blooming garden in spring (Straight Cut)

Snake weaving through grass → Amazon River winding through rainforest (Straight Cut)

Rain on Amazon foliage → Oasis spring in desert (Flickering)

Wind sweeping wildflowers → Ripples spreading across pond (Straight Cut)

Petra's glowing canyon → Sunlit stained glass in cathedral (Straight Cut)

Market stall of spices → Painter mixing oil colors (Alpha Blended)

Falling orange leaf → Paw print etched in ground (Straight Cut)

Guacamaya soaring through jungle → Colombian flag waving on hilltop (Straight Cut)
Comparison with Baselines
Below, we compare results from MatchDiffusion with three baseline methods across three sample prompts. Each row corresponds to a prompt, and each column shows the results generated by a specific method.
Cog Vid-to-Vid
SMM
MOFT
MatchDiffusion (Ours)

Parchment sunset - V2V

Parchment sunset - SMM

Parchment sunset - MOFT

Parchment sunset - MatchDiff

Metro conveyor - V2V

Metro conveyor - SMM

Metro conveyor - MOFT

Metro conveyor - MatchDiff

City fridge - V2V

City fridge - SMM

City fridge - MOFT

City fridge - MatchDiff
Captions:
- Row 1: Parchment catching fire → Setting sun dipping below horizon
- Row 2: Metro speeding through station → Conveyor belt in factory
- Row 3: City skyline at sunset → Fridge stocked with fresh items
Sampling with MatchDiffusion
Below, we several alternatives for the same match-cuts by sampling with different seeds.
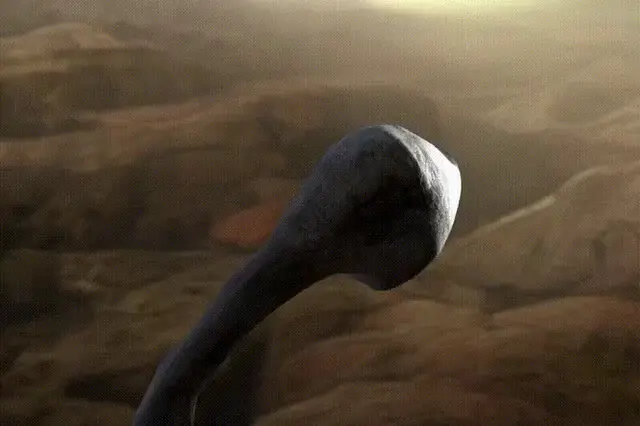
Fossil sample 43

Fossil sample 44
Fossil sample 60

Fossil sample 74

Ember sample 42

Ember sample 43

Ember sample 48

Ember sample 52

Flower sample 1000

Flower sample 1004

Flower sample 1014

Flower sample 1011
Captions:
- Row 1: A bone-like fossil thrown to the sky. → A sleek spaceship flying through the space.e
- Row 2: A glowing ember flickers within a campfire. → A city skyline lights up at dusk.
- Row 3: A flower blooming in the dark. → A video of fireworks over a city.
Analysis on number of Joint steps (K)
Below, we show a few examples of the effect of the number of shared steps for three different samples.
K = 0
K = 10
K = 20
K = 50

Butterfly sample 0

Butterfly sample 10

Butterfly sample 20

Butterfly sample 50

Parchment sample 0

Parchment sample 10

Parchment sample 20

Parchment sample 50

Ripples sample 0

Ripples sample 10

Ripples sample 20

Ripples sample 50
Captions:
- Row 1: Autumn leaf falling → Butterfly fluttering
- Row 2: Parchment catching fire → Setting sun dipping below horizon
- Row 3: Vintage steam train → Tranquil river winding through forest
Boundary Frames Visualization
Below, we visualize the boundary frames for four different samples.
The left image corresponds to the last frame of the first video, and the right image corresponds to the first frame of the second video in the Match-Cuts.

First Frame (Video 2)

Last Frame (Video 1)

First Frame (Video 2)

Last Frame (Video 1)

First Frame (Video 2)

Last Frame (Video 1)

First Frame (Video 2)

Last Frame (Video 1)
Stable Diffusion 1.5 + MatchDiffusion
We also experimented using the two MatchDiffusion paths Joint + Disjoint with the Stable Diffusion 1.5 model.
Below, we visualize the frames pairs. We observe a similar pattern as the two images share overall structure while being semantically divergent.
Citation
@InProceedings{Pardo2024,
title = {MatchDiffusion: Training-free Generation of Match-Cuts},
author = {Pardo, Alejandro and Pizzati, Fabio and Zhang, Tong and Pondaven, Alexander and Torr, Philip and Perez, Juan Camilo and Ghanem, Bernard},
booktitle = {ICCV},
month = {October},
year = {2025},
}
Acknowledgments
The research reported in this publication was supported by funding from King Abdullah University of Science and Technology (KAUST) – Center of Excellence for Generative AI, under award number 5940.
We thank the reviewers for their constructive feedback, in particular for suggesting alternative transition strategies between the two videos.

































